From the Terminal
Getting MacOS style hotkeys working in GNU/Linux
Over the years I've used every operating system. Sometimes all at once. Recently I've taken to using Linux as my primary desktop operating system. Everything I need runs natively on Linux and because I have full control over my environment I never have down time due to forced updates. This is my desktop after all so I'm really switching from Windows where the Control key modifier paradigm is more or less the same as Linux. Still I didn't want to compromise on anything with this new configuration and there was one thing missing from my Macbook that I really wanted.
Of course what I'm talking about is the Command key or more colloquially known simply as the Apple Key and all the shortcuts and hot keys built into macOS that make it such a joy to use.

"Linux lets you change whatever you want."
Is a common thing that people say to bring up a positive aspect of GNU/Linux. Is this actually true though? Take for example my issue at hand: Changing copy/paste hotkeys for all programs. In truth, some tasks are so big in their scope few users would ever be capable of accomplishing them. At least not without a lot of contextual knowledge.
Getting macOS style hotkeys is actually an extremely difficult task in Linux. Especially when you want to avoid faking it by binding some keys to other keys on a per application basis.
Then there's the question of why do it at all?
The truth is I just got tired of accidentally sending SIGINTs when switching to terminal and then accidentally triggering the wrong thing when switching out of terminal. I've just gotten so used to not having to context switch my brain in macOS between programs. It's one of the things that truly makes my Macbook Pro more pleasant to use.

So that's my first reason. Muscle memory.
My second reason is simply that Command/Meta is directly next to the space bar and I just like having a shorter stretching span for my hand.
Making it work
For the most part GUI applications written for Linux tend to make a lot of assumptions about what hotkeys can and should be in a very opinionated way. Some types of programs require full customization (like code editors) while others like browsers tend to force certain hotkeys. Desktop managers do provide their own hotkey bindings. For example most KDE based applications will use your settings from KDE's "System Settings" to set hotkeys. Meanwhile in Gnome you can use dbind to set your keybinds.
Of course Cut/Copy/Paste is not enough. It would actually be quite jarring to use CTRL+T for opening a new tab immediately after using Command+V to paste something. Indeed if you go down this path you'll end up having to redefine your hotkeys for well..... everything. It is unfortunate as well that applications these days are extremely hostile to user settings.
Despite the hurdles in front of me I decided to try to make it work.
The first thing I did was swap Left Alt and Left Meta on my keyboard. This was actually pretty easy to do with keyboard mapping configs with the KDE GUI simply known as "System Settings". This was simply to make my normal windows keyboard place the buttons in the positions a real mac keyboard would have. None of this is necessary if you have a real Apple layout keyboard. This setting is only active while in my X session so any alternative TTYs would revert back to my stock layout. If I had a real Apple layout keyboard though this is not necessary at all.

This setting is saved to the text file ~/.config/kxkbrc.
$ cat kxkbrc
[Layout]
DisplayNames=
LayoutList=us
LayoutLoopCount=-1
Model=pc101
Options=altwin:swap_lalt_lwin
ResetOldOptions=true
ShowFlag=false
ShowLabel=true
ShowLayoutIndicator=true
ShowSingle=false
SwitchMode=Global
Use=true
Now with this setting I am able to fake the same key mapping as a real macOS keyboard would have in my desktop session. So far so good. Now I manually changed all my hotkeys in my code editors, terminal applications, and even in the System Settings app I just mentioned to set global hot keys for all KDE applications. This took some time but was very straight forward for the most part.

I went above and beyond even changing my shortcuts for things like Select All.
While this worked for KDE applications I had to also make this change for GTK+ based programs as well. Luckily this would also cover Chrome, Discord, Elements, and a number of other Electron based programs that I use on a regular basis.
I was lucky that VSCode let me change everything but it was very annoying have to redo all the system based hotkeys like Set cursor to start of the line (in macOS this is Meta+Left Arrow) for each and every place I wanted to use it.
Some websites also use Meta+C for example in Github hitting Meta+C will actually take focus and bring you to the Add Comment UI when in a thread so sometimes on Github.com even with Firefox set to use Meta+C to copy something I am not actually able to use my hotkey because the website overrides it.
With GTK I ended up editing `~/.config/gtk-3.0/gtk.css` and setting these hotkeys.
@binding-set gtk-super-cut-copy-paste
{
bind "<super>x" { "cut-clipboard" () };
bind "<super>c" { "copy-clipboard" () };
bind "<super>v" { "paste-clipboard" () };
bind "<super>a" { "select-all" (1) };
bind "<super>z" { "undo" () };
}
* {
-gtk-key-bindings: gtk-super-cut-copy-paste
}
I might add more but for now this got me to where I wanted with most GTK+ applications. Note that if you plan to run any of programs designed to run as root that use GTK+ such as GParted you should also link or copy this config file to the root account home directory as well.
So in the end it is possible. I was able to achieve what I wanted with all but one program. But it was a huge pain. It's really difficult to figure out what settings do what in a Linux environment even when there is documentation. It's typical for documentation to exist for say GTK+ 2.0 and GTK+ 3.0 but there is no over arching best practice guide for what one should do when they want to cover all programs in an environment.
It Doesn't Have to Be This Way
The Linux ecosystem can and should do better. The ability to do whatever you want is a double edged sword where even though you can in theory change things, in practice however, sometimes changing things is so onerous that staying sane in the process is a task in itself.
So please if you are a Linux user space developer check the GTK+ 2.0 (~/.gtkrc-2.0), GTK+ 3.0 (~/.config/gtk-3.0/gtk.css) and KDE global shortcut configs (~/.config/kdeglobals) when you probe for the environment during startup so that people can choose their own hotkeys for their desktop environment or simply use the C libraries of each and use the hotkeys present.
Better yet, if you are a developer that already supports various input methods for macOS, Linux, and Windows you can simply provide a toggle for users.
It would be beneficial to Linux Desktop environments to agree to a standard config file for hotkeys allowing users to bind keys as they see fit rather than lurching from one weird keybinding config to the next with no centralization to speak off.
Using Meta instead of Ctrl for Cut, Copy, Paste shortcuts in Firefox for Linux
Set these in about:config
accessibility.typeaheadfind isn't blocked by Meta + C / Meta+V so we need to turn it off.
ui.key.generalAccessKey: 224
ui.key.accelKey: 91
accessibility.typeaheadfind: false
accessibility.typeaheadfind.autostart: false
A few useful life cycle tracking variables every ORM should have
Right now I'm in the unusual position of being responsible for maintaining two different ORMs libraries. Occasionally I want to implement a feature that exists in one of them in the other. One such feature recently came up and I think this is something that all ORMs would benefit from whether or not they are custom written or maintained by the community. In fact after looking into things it looks like some of these already exist in one way or another in some of the most popular ORMs available.
Let's take a look at some of them.
- isNew - False by default. Set to true only when an object that isPhantom is saved
- isUpdated - Set to true when an object that already existed in the data store is saved.
- isPhantom - True if this object was instantiated as a brand new object and isn't yet saved.
- isDirty - False by default. Set to true only when an object has had any field change from it's state when it was instantiated.
Some of these properties might already exist in one form or another in your frameworks. They are simple to implement by simply adding them to the functions in the Model class at different points in the life cycle of the object. Most of them are extremely simple but as you'll see with isDirty consideration might get extremely complex in a hurry.
isNew
The point of isNew is to be able to tell that this object was created during this script execution but was previously saved. Before save it's obvious that an object is new by it's missing primary key. However after saving all evidence of this object being new has been erased. This property lets you know that this object was previously created by you so that if it's part of a large array you can iterate over the items and still know which objects are the "new" ones.
Let's take a look at how this might be useful.
<?php
$cars = Car::GetAll();
$car = new Car();
$car->save();
$cars[] = $car;
foreach($cars as $car) {
if($car->isNew) {
// do something special to the objects we created above even if we saved them since then
}
}
isUpdated
This one is pretty simple. This let's us know something that was already in the data store, has been updated by us since initialization.
isPhantom
Let's us know if we need to Update or Insert this model when saving the object. If Insert this gets set to false right after.
Implementation Details
Let's table isDirty for now and come back to it. For now let's take a look at some code. Here we do a pretty basic boiler plate for the variables we want and how they are manipulated later on.
__construct()
<?php
public function __construct(..., $isDirty = false, $isPhantom = null /* you can
implement these differently but the hydrator needs some way to set these
for an instantiated object */)
{
$this->_isPhantom = false; // this should be set by your model hydrator at time of hydration
$this->_isDirty = $this->_isPhantom || $isDirty;
$this->_isNew = false;
$this->_isUpdated = false;
}save()
public function save() {
if ($this->isDirty) {
// create new or update existing
if ($this->_isPhantom) {
// do insert
$this->_isPhantom = false;
$this->_isNew = true;
} else {
// do update
$this->_isUpdated = true;
}
$this->_isDirty = false; // only if you don't use a function to detect this
}
}So here we can see how it all comes together from initialization to storage. But what about isDirty? What's so complex about it? Well let's take a look.
isDirty
There's multiple ways to implement isDirty and both have positive aspects as well as drawbacks. If your ORM uses direct PHP object properties that map to fields only one is open to you anyway. Let's take a look at what I mean.
If you use an ORM where the fields are not object properties and are in-fact "not real" that means that you can actually implement this as a simple boolean.
For example:
<?php
public function __construct(...) {
$this->_isDirty = false;
}
public function __set($field,$value) {
$this->_isDirty = true;
...
}
public function save() {
...
$this->_isDirty = false;
}The best thing about this method is how light is it on the run time. You simple need one boolean worth of memory space for each object. Unfortunately this method also can't tell when the field was set back to it's original value or if a field was edited but the value remained the same as it was before. So while you may save some memory up front in your run time you might end up wasting a lot more memory resources in your database updating records that have no new data or simply slowing down batch processes sending writes to the database that it will end up wasting time. Furthermore this only works with dynamically allocated "magic" properties.
Your other option is to use a method to test each field for a change and return true or false. Okay but how? By keeping a copy of the "original" field values of course. And this is where this method starts to show it's down sides. You actually end up approximately doubling the amount of memory you need to make this happen. Plus that itself has complexity. For example do you change your original variables after a save? Unfortunately the answer is yes. Simple because you want isDirty to go back to false after running a save. Some things are free though. Any object that is a phantom is dirty by definition.
public function isDirty()
{
if ($this->isPhantom) {
return true;
}
$fields = static::getFields();
foreach ($fields as $field) {
if ($this->isFieldDirty($field)) {
return true;
}
}
return false;
}
public function isFieldDirty($field)
{
if (isset($this->_originalValues[$field])) {
if ($this->_originalValues[$field] !== $this->$field) {
return true;
} else {
return false;
}
}
return false;
}Of course you'll need to set_originalValues in your object during hydration. New objects won't start tracking this until immediately after save. It's worth noting that Laravel's Eloquent implements isDirty in a very similar way.
Closing Thoughts
Most ORMs implement these one way or another out of necessity however it would be nice if ORMS could standardize on these and perhaps start using the same terminology surrounding them. Is dirty is optional for many ORMs when it's beneficial to force a save() even if nothing has been changed simply to updated the modified at timestamp for the record in the data store. Still a well designed ORM should let you do both depending on your needs.
Ignoring SAPI with Symfony VarDumper
<?php
$varCloner = new \Symfony\Component\VarDumper\Cloner\VarCloner();
$cliDumper = new \Symfony\Component\VarDumper\Dumper\CliDumper();
echo $cliDumper->dump($varCloner->cloneVar($query), true);
Quick way to output full text instead of HTML when SAPI is not CLI
The case for system wide dependency injection in PHP
So first let me clarify what I mean when I say "system wide dependency injection".
The typical PHP Composer project offers "project-wide" dependency injection. The autoloader is made for your project and you simply require that one file. However, with other languages it's typical for dependencies to be in a shared folder for the entire system.
In composer we could use a "global" directory in global mode as well like this.

The problem is it's only global "for you". So if you decided to run composer global for another user all the packages you have installed would be different. So it's not global. Not even system-wide really since the home directory might not allow read from other users.
So neither of these modes in composer are really system wide.
In other languages system wide dependencies are stored like so.
For example here's Python.

Perl too.

And Ruby.

Okay so what about PHP?
To fill this hole some Linux developers who choose to include PHP code directly in the system have started to build packages for their distro's package managers.

Here we have the install script for symfony-console in portage. You can see the files are actually stored in /usr/share/php. Unfortunately these files don't have automatically generated autoloaders by composer making integrations very messy.

Portage users aren't the only ones.

Clearly some users choose to install PHP code for use system wide.
/usr/share/ or /usr/lib
Let's check the Linux Foundation's documentation on the topic.


Even though PHP code isn't architecture dependent, in my opinion, it's more of a library for programming so to that end I think it makes more sense to use /usr/lib or in my case /usr/lib64 just like other scripting languages. It would also avoid the messy businesses of integrating with none composer package managers.
I decided to go ahead and experiment with this idea.
I forked composer and made a composer system command. Just like composer global sets the folder to ~/.config/composer/, with the system command it instead sets the folder to /usr/lib64/php or /usr/lib/php if they exist in that order. You must create /usr/lib{64}/php yourself.
The fork of composer is available here: https://github.com/hparadiz/composer
I then loaded in some really awesome PHP libraries.

With this newfound power to no longer have to bundle libs with my scripts I made a database backup utility for this blog in 50 lines of code with SSH tunneling that drops sql.gz to my local home folder.
Feel free to fork it and make your own.

I had the script output to a Dropbox folder since I have it running already. Which is awesome since that's three locations and one of them is managed for me. I'll be hacking at this some more but for now I like this starting place.
I like that this script is fully portable and editable wherever it is. If I compile it to a phar it would be difficult to make changes or loop it for multiple databases without setting up an entire build configuration despite that logic being relatively simple even for a novice.
For me, at least, the reasons to allow composer to manage dependencies at a system wide level instead of having other package managers do it is self evident.
Installing XDebug on anything for VSCode in 5 minutes (XDebug 2.x)
Update 2/25/2021: This guide is for XDebug 2.x only.
I see a lot of over complicated guides on XDebug so I'll simplify things real quick for everyone.
Visual Studio Code has debugging support out of the box. Click on the Debug icon in the left bar (OS X: ⇧⌘D, Windows / Linux: CTRL+SHIFT+D) then click on the cog icon which should open your launch.json file or create one if none exists.
You must have the PHP XDebug extension installed of course.

Now add this to your launch.json file you have open:
{
"type": "php",
"request": "launch",
"name": "Listen For XDebug",
"port": 9000,
"pathMappings": {
"/var/www/": "${workspaceRoot}"
},
"xdebugSettings": {
"max_children": 256,
"max_data": -1,
"max_depth": 5
},
"ignore": [
"**/vendor/**/*.php"
]
}Make sure you change /var/www/ to where your code is on your local server.
Set this in your php.ini
[xdebug]
xdebug.remote_enable = 1
xdebug.remote_autostart = 1
xdebug.profiler_enable_trigger = 1You might need to do it twice. Once for CLI and once for PHP-FPM!
Typical locations for your php.ini file:
- Linux: /etc/php/{$version}/php.ini
- macOS (Homebrew): /usr/local/etc/php/{$version}/php.ini
Don't forget to restart php-fpm!
Now start the debugger by hitting the green play button.
Infinity
I always think about how if you count from one to infinity; within that infinity of numbers exists every movie, book, photograph, software or game, video, song or sound, work of art, insignificant doodle, and master piece of conscious thought in every file format you can image and yet to be invented and never to be invented.
All of that is in this simple loop
i=1;while(i) { i++; }
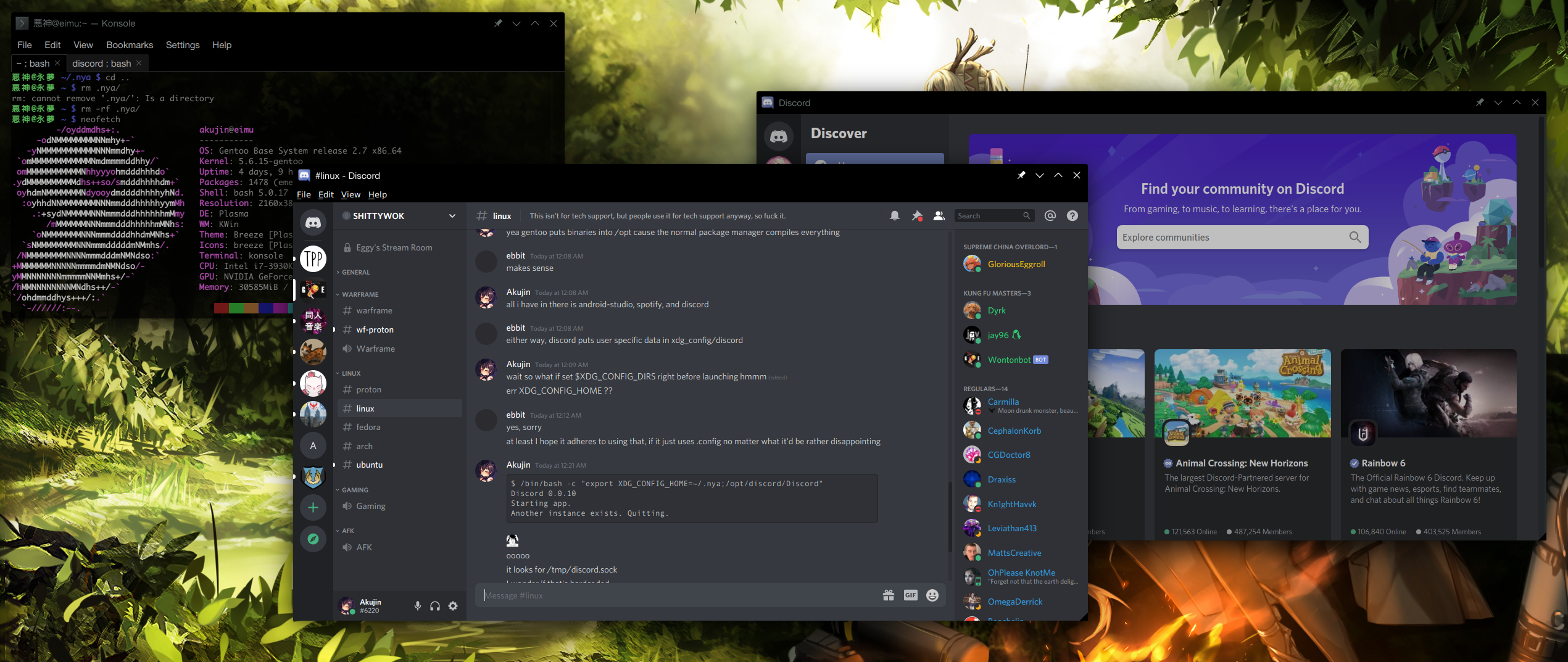
Running Multiple Instances of Discord in Linux
In Linux Discord stores it's data in XDG_CONFIG_HOME which is ~/.config by default. It also uses /tmp for a discord.sock file which it uses to determinate if there is already a running process.
Simply set both TMPDIR and XDG_CONFIG_HOME to an alternative and launch discord.
/bin/bash -c "export XDG_CONFIG_HOME=~/.nya; export TMPDIR=~/nya; /opt/discord/Discord"
In Gentoo Discord installs to /opt so change that to your location.
Solving Dependency Slot Conflicts in Gentoo Elegantly
Sometimes when you want to emerge something or upgrade something you will have dependency slot conflicts like this example.
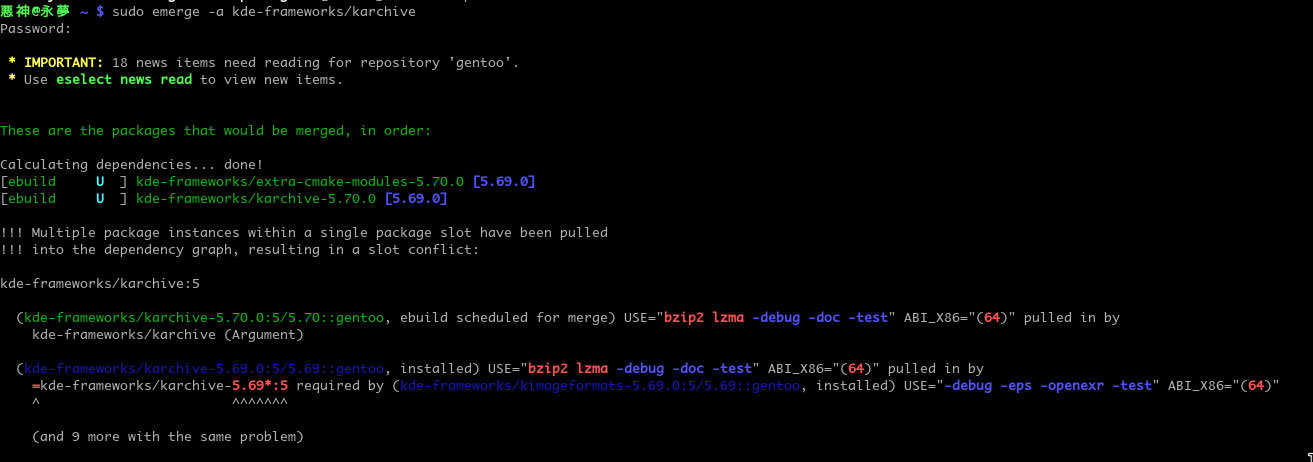
To fix this problem you'd need to emerge all kde-frameworks/* packages you currently have installed to upgrade them all at once since it's all part of one framework.
The following commands let you do so with ease.
equery l kde-frameworks/* -F '$category/$name'
The output of which you can send right into emerge like so.
sudo emerge --ask -1 --verbose-conflicts $(equery l kde-frameworks/* -F '$category/$name')
Now you'll hopefully get a clean emerge.

Age of Empires II: Definitive Edition on Linux
Get the Linux version of Steam and enable this in settings

This will unlock the ability to download and install any title even if they are Windows only titles.
Now you'll be able to enable a custom compatibility tool in the settings for the game.

I've been playing the game with Proton 5.8-GE-2-MF which you can get at https://github.com/GloriousEggroll/proton-ge-custom.
You will also need to delete these files to avoid lockups from playing wmv files in-game. Otherwise the game runs flawlessly.
rm -rf ~/.steam/steam/steamapps/common/AoE2DE/resources/_common/movies
rm -rf ~/.steam/steam/steamapps/common/AoE2DE/resources/en/campaign/movies
If you are having issues make sure you have the most recent version of DXVK, Proton, Wine and your video card's driver.