From the Terminal
I "Rewrote" My ORM Again with AI. And Ended Up Benchmarking Every PHP ORM in the Process.
You may or may not have read my other blog posts about how
How I gamified unit testing my PHP framework and went from 0% unit test coverage to 93% in 30 days
(7 years ago!) or about how
PHP attributes are so awesome I just had to add attribute based field mapping to my ORM
I've been writing ORMs by hand for 20+ years. This isn't even the only one I've worked on. ORMs for me are like puzzles so I am not kidding when I say I think about them when I'm just quietly going about my day. So with ML I've been able to basically get to where I want to be with Divergence. If you prefer blog posts written by humans I can attest that nothing in this post is written by AI and every metric presented in this post is deterministic and readily quantifiable.
Where's the benchmark result?
Here: https://the-php-bench.technex.us/runs/1
Okay so what? How is this better than other benchmarks? It's obviously vibe coded.
I hand curated a very specific architecture for how it works rather than simply that it works. Every framework has it's own vendor. Tests run in a sub process. Tests run one at a time instead of in parallel. The benchmark collects clear information about the hardware in order to provide a clear baseline. Results are logged appropriately locally and optionally uploaded to that site I put together above. Six models were hand designed in order to stress the various database types in different ways and that shows clearly in the profile of the result set.
Code Quality
I tend to go into way too much detail about my ORM that no one uses so if all you care about is the benchmark results of every other framework just look at the benchmark results above. But if you care about improving code complexity read on.
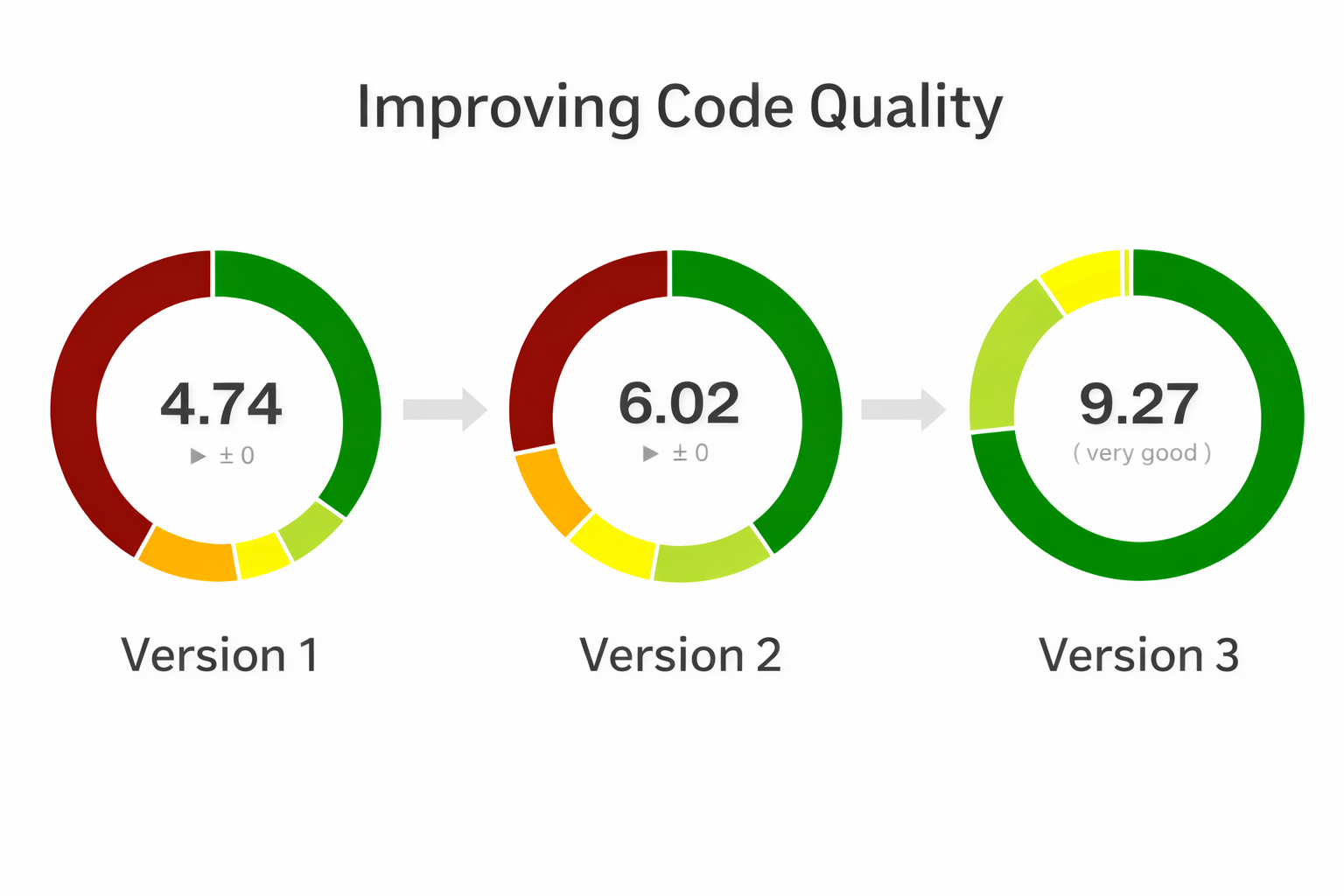
Prior to version three I had already been wanting to improve code quality and was already going in that direction.
In version three I was able to find ways to improve code quality substantially but it all built on top of the work I had done by hand moving from Version 1 to 2.
Version 1 of Divergence was mostly dominated by a large ActiveRecord monolith class paired with a MySQL class. Together they were able to stand up an impressive PHP 5.x era ActiveRecord ORM with a good track record that stood up well through PHP 7.4. PHP 8 however introduced attributes and there is where I started to think critically about Code Complexity and way of breaking up the code into smaller chunks with lower complexity.
Code Complexity? What are you talking about?
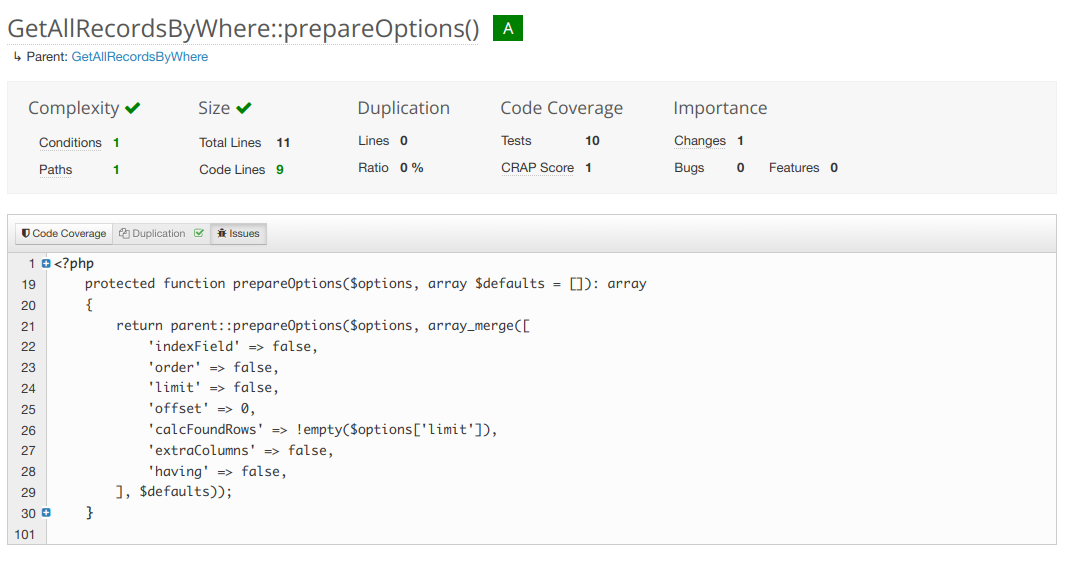
Code complexity is a measure of how many pathways your code can take. The fewer, the simpler, the easier it is to write a unit test that covers 100% of the things your function can do.
Above is a fairly simple and not very complex function.
On the other side of the fence we've got the most complex function in the framework at the moment which is my next target for refactoring.
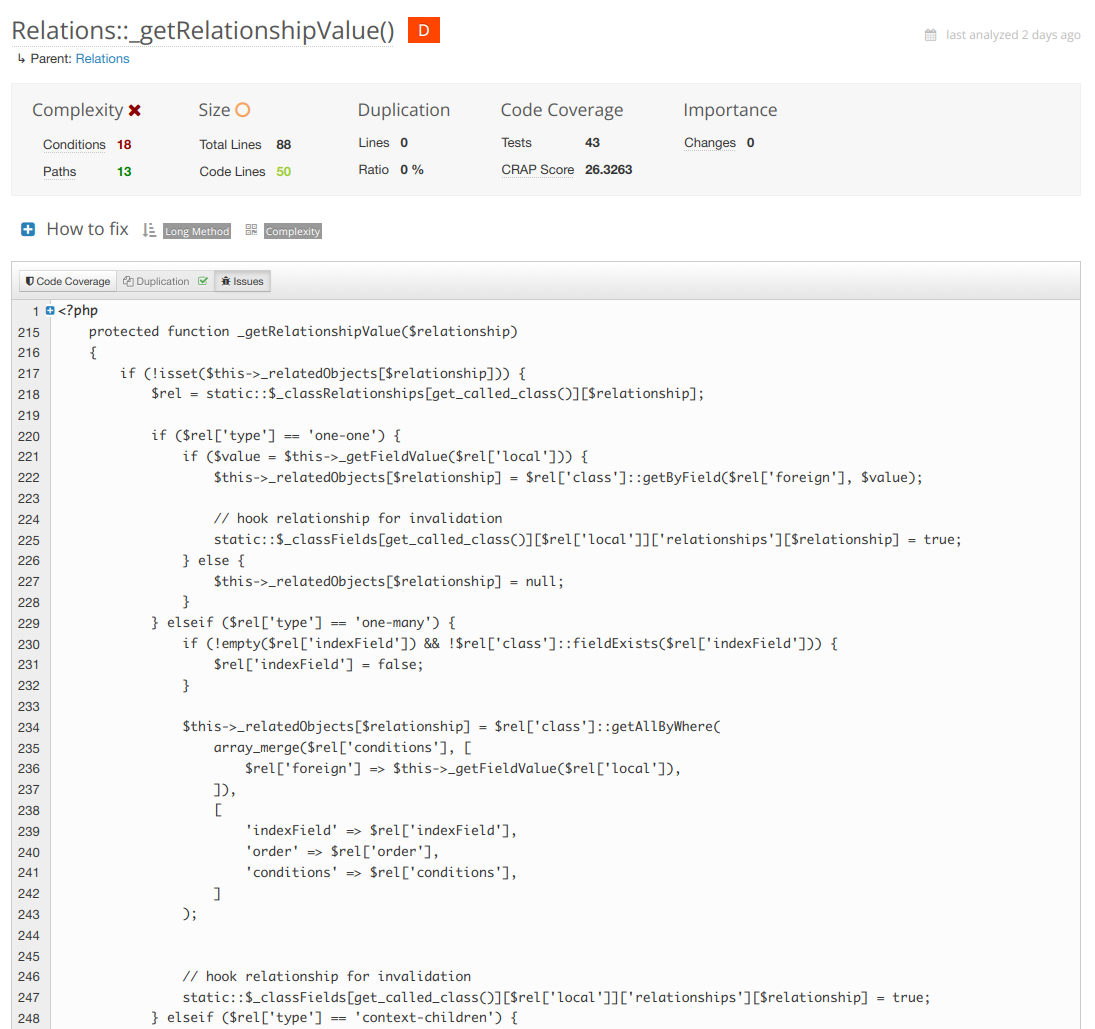
In this case the refactor is obvious. Break up each of the relationship types into smaller method calls inside the same class. Each one responsible for only it's own thing. Complexity drops. Your tests become far simpler and targeted.
Above is the worst class now... in version three. But back in version one the code was in a way worse shape with complexity.
Version 1 of Divergence - Large Monolith Classes
In 1.0 ActiveRecord was handling almost everything including mapping type values to MySQL type values so in 1.1 I introduced the "FieldSetMapper" abstraction. which allows a model to set it's own Field Mapper if necessary. A field mapper handles how types are cast between the SQL query and PHP data types. This lowered ActiveRecord's complexity in a great direction but it was still responsible for instantiating and hydrating new objects, getters, as well as the life cycle of the object. Pretty much still a monolith. Not great for code complexity.
The next thing to refactor was how queries were being written. In ActiveRecord and VersionedRecord there where only a handful of spots where a SELECT, UPDATE, INSERT, or DELETE was being generated so it was an obvious spot to start doing query writing through a class. I implemented __toString() here so all the existing string handling just keeps doing what it was doing. Tests passed no problem. At this point the ground work was laid for being able to implement other storage engines besides MySQL for the first time. This is also where I started to think of "Getters" as separate from the ActiveRecord class.
There are two types of "Getters" in ORMs. One is for getting a field, property, meta data, or relationship value internal to an object instance. The other type of "Getter" is when you want to pull records from your storage engine and have them be instantiated in your code. That second type is the one I am referring to here.
In CS-coder speak this type of Getter is essentially a factory. A place where we grab data out of the storage engine like MySQL and then shove that data into PHP objects. Getters have two parts. A query part and a hydration part. These types of Getters are broken up further into two types. Multiple records and single records. Some of them like getByWhere have a direct all version getByAllWhere. The only difference is getting one of itself to multiple of itself. So here they are. The object instantiation getters of Divergence.
| Single | Multiple |
|---|---|
getByID |
|
getByHandle |
|
getByContextObject |
getAllByContextObject |
getByContext |
getAllByContext |
getByField |
getAllByField |
getByWhere |
getAllByWhere |
getByQuery |
getAllByQuery |
getRecordByField |
|
getRecordByWhere |
getAllRecordsByWhere |
getAllByClass |
|
getAll |
|
getAllRecords |
Okay so why? Why do that?
A lot of ORMs just do this. A factory class has the getters and spits out Employee objects. Simple. Well in the best case. Something like this.
<?php
$employees = new EntityManager('Employee')->all();In Divergence I do this:
<?php
$employees = Employee::getAll();This has not changed since Version 1 either. From the predecessor of this framework Emergence to now this code is still valid. I'm not gonna say my changes haven't broken user space but they certainly did so in ways that are easy to port. When you have these getters registered as static methods under your class you get a global access to these models from anywhere in your code. They become singleton globals we can use anywhere.
In version 2 of Divergence I started to abstract them out by making them a trait you could attach to your Models. The default Class "Model" would automatically assign them so the global method calls persisted through the refactor and again no tests were harmed. Yet now they were not in ActiveRecord and made the code far less complex.
It became immediately apparent that every single function in the table above was either using instantiateRecord or instantiateRecords. After running the query the return data had to be converted to PHP objects and that's where it happened. So along with the above methods I was able to also move hydration into the Getters trait and a few other helper methods. They technically still accessed field and relationship mappers in the ActiveRecord class but hydration was still something we could move out of ActiveRecord as long as the mapping field mapping was calculated once. This is around the time when I wrote my blog post about attribute field maps in PHP 8.
At the same time I also converted my controllers to use PSR7 and PSR15 handlers and emitters. The "old school" way is to just echo, print, and run header() whenever you please in your controller. The new way is to generate an HTTP controller object, set everything, and then pass it to an "Emitter" that does the printing and http handling. To be honest that deserves it's own blog post but suffice to say it lowered complexity further. At the same time I added Media handling classes that needed heavy refactoring. But at least for the moment I was able to take the wins and get the score from a 4.7 to a 6 with these changes. Still to hit the 9 I was looking for it would take some heavy thinking on how to tackle the next iteration. And all this was BEFORE a single AI algorithm had been used.
So in version 2 I identified these goals for version 3.
- I want to support SQLite and PostgreSQL
- To do so the Connection must be aware of it's engine and be tied to a given Model's instantiation and Hydration and the Query Writer needs to know about the Connection's Storage Engine in order to write proper syntax.
- By providing a Factory class we can keep that state with the instantiation and hydration cleanly.
- Factory classes also make it easier to test things in isolation.
- Using __call we can create different types of methods that used to live in ActiveRecord that are converted to their own classes.
- Getters that used to exist in ActiveRecord can still run statically if they are registered with the Model using __call.
- What's left after removing these things from ActiveRecord is events and those can then cleanly be moved into their own classes as well.
All this abstraction sounds like a lot but we went from ActiveRecord doing manual INSERT and UPDATE query writing hardcoded MySQL syntax. Instead now when we cast from SQL to PHP and back and the system is neatly organized and any overrides can happen in the most appropriate place. Super simple to test. The query writers for each storage engine work against whatever the active connection is and only have overrides when necessary.
Should Models Even Have Getters and Setters to Get Records Of Themselves From the Storage Engine?
PHP is inherently procedural and owing to it's roots. Because it's procedural things are happening one at a time from beginning to end. When scaling you might have a read replica of the database that is used as a backup. In that case you might even run something like setConnection(). When your secondary connection is the same storage engine things are easy but what if it's a totally different type of SQL? That's basically why it's better to have a Factory or "Entity Manager". You might want to create two for the same Model for two different connections or more than that even. But...... 99% of projects won't ever need it. So I want to serve both schools of thought. And that is why in version 3 of Divergence I decided to introduce a Factory class for the first time. Now all the connection handling, storage engine SQL translation, mapping, and object hydration doesn't have to live in ActiveRecord. The thing is you can still use __call to build "fake" methods so I did just that for the Getters that used to live in ActiveRecord. So you can still use them and it will make you the Factory in the background but if you really need the abstraction you can also make the factories and manage them manually.

New Hydration Method
In version three besides the difference in where this stuff is happening I also abstracted out the way that objects are instantiated.
In Divergence 1 and 2 we did the classic late static binding.
Anyway here's version 3 of Divergence.
Honestly I'm not even ready to pin this version of Divergence 3 as "final". There's several new things I wanna add but well meh ship it. It's running this blog in any case and doing it quite well.
Here are my benchmarks right now
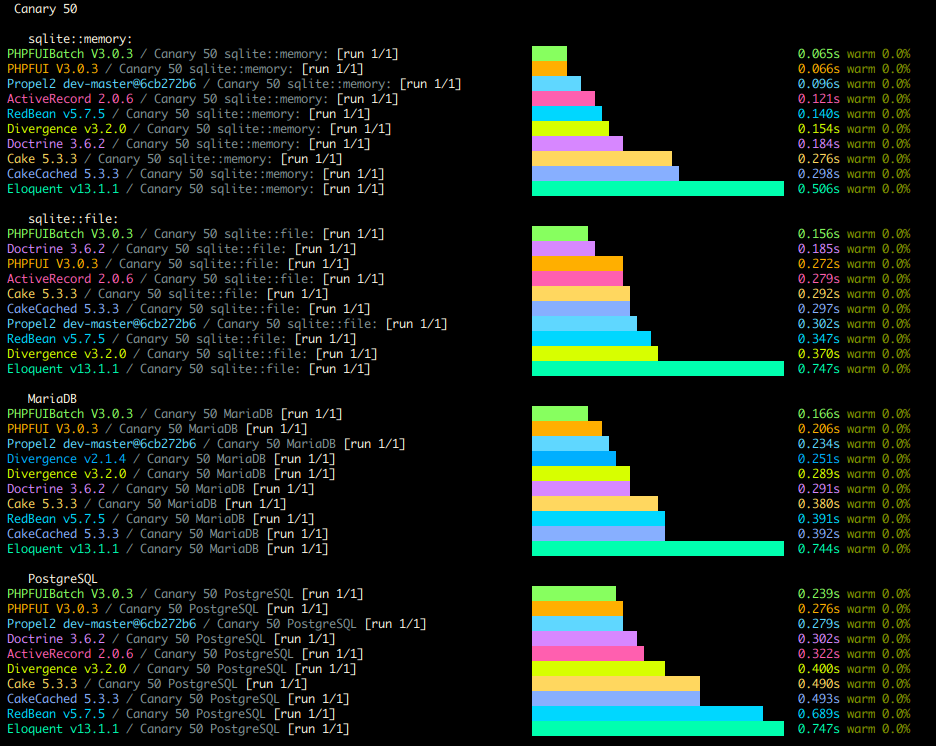
In the process of doing all this I really wanted a good profiler and test case so I ended up building a new PHP Benchmarking Suite which I call "The PHP Bench". The screenshot above is the results command doing it's thing on the CLI. But then I made a website for it where results can be viewed online.

I'm particularly proud of the architecture of this benchmark. I hand designed the Models to simulate several types of data. Canary in particular handles every type of field my framework supports. But then I also have fixed ints, variable strings, and fixed strings, among other benchmarks you can run. Every type shows a clear and distinct performance profile among the various frameworks.
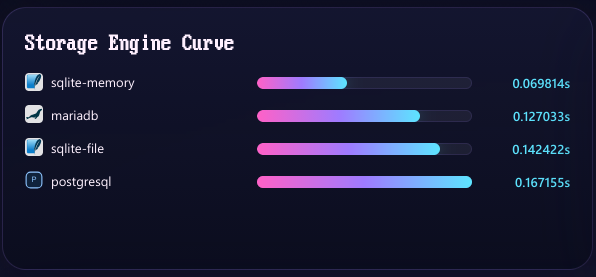
Each framework gets their own composer.json and isolated vendor path that only gets required for their individual test so none of the frameworks can really interact with each other or cause conflicts. The findings were completely unexpected to me but I'm proud to say my self made ORM is among the world's best.
Now that I have a profiler and benchmark I can use my next step is to scaffold some first to save() and some first to query profilers against some of these and see if I can shave another 0.02-0.05 ms per operation. I never really thought I'd get to hit this milestone so soon. So that's nice.
I honestly feel like a dog that finally caught the truck. Now what.

Haha just kidding. There's so much I can do with this now! With agents I can just throw the docs at it. I even got a minimal context size one written up for MVPs. I've already got this blog working of course but what's next? You can't see it but I already got my admin page slightly tricked out.
I didn't even use react. I told it to use classic jquery ajax on top of vanilla javascript so it's dead simple.
So what else is there to do? I've been wanting to tackle some federated things and see how far I can get. In particular I think it would be fun to turn this blog into a federated node and implement the ActivityPub protocol.
Stuff You Can Play With
PHP attributes are so awesome I just had to add attribute based field mapping to my ORM
I wrote this post to talk about the architectural decisions I had to make in upgrading my ORM recently to PHP8 as well as the general justification for using an ORM in the first place as a query writer, runner, and object factory and why I consider attributes to be the holy grail of ORM field mapping in PHP.
Writing Queries
I've always been fascinated with moving data in and out of a database. I've been at this from PHP4 days, you know. As hard as it is to believe even back then we had a testable, repeatable, and accurate way of pushing data into and out of a database. I quickly found myself writing query after query.... manually. At the time there was no off the shelve framework you could just composer require. So I found myself thinking about this problem again and again and again and again.
Put simply when you write SQL queries you are mapping variable values in memory to a string. If you are one of those people that claims that an ORM is bloat you'll find yourself writing hundreds of queries all over your projects.
If you've ever imploded an array by a "','" but then ended up doing it in dozens or hundreds or thousands of places the next logical step is to stop rewriting your code and write a library.... and hence an ORM is born. An ORM is an absolute statement; that "I will not rewrite code for handling a datetime" and then actually following through.
To make this happen you must write some sort of translation layer from PHP types to SQL types. In most ORMs this is called mapping.
Before PHP8 the typical thing to do was to use a PHP array defined statically containing all that information. Like this. In fact this is from Divergence from before version 2.
public static $fields = [
'ID' => [
'type' => 'integer',
'autoincrement' => true,
'unsigned' => true,
],
'Class' => [
'type' => 'enum',
'notnull' => true,
'values' => [],
],
'Created' => [
'type' => 'timestamp',
'default' => 'CURRENT_TIMESTAMP',
],
'CreatorID' => [
'type' => 'integer',
'notnull' => false,
],
];But this kinda sucks. There's no way to do any auto complete and it's just generally a little bit slower.
A few frameworks decided to support mapping using annotations (an extended PHPDoc in PHP comments) and even yaml field maps but those are all just bandaids on the real problem. Which was that there was no real way to provide proper field definitions using the raw language's tokens, instead relying on the runtime to store and process that information.
Attributes
So that's my long winded explanation about why my absolute favorite feature of PHP 8 is attributes. Specifically for ORM field mapping. Yea really.
#[Column(type: "integer", primary:true, autoincrement:true, unsigned:true)]
protected $ID;
#[Column(type: "enum", notnull:true, values:[])]
protected $Class;
#[Column(type: "timestamp", default:'CURRENT_TIMESTAMP')]
protected $Created;
#[Column(type: "integer", notnull:false)]
protected $CreatorID;This is sooooo much cleaner. Look how awesome it is. Suddenly I have auto complete for field column definitions right in my IDE!

Now the code is cleaner and easier to follow! You've even got the ability to type hint all your fields.
Once we take field mapping to it's logical conclusion it becomes practical to simply map as many database types as we can into the ORM. We can even try to support all of the various field types that could be used in SQL and represented somehow in PHP. Of course to make this happen it becomes necessary to tell the framework some details about the database field type you decide to use. For example you can easily see yourself using a string variable type for varchar, char, text, smalltext, blob, etc but most ORMs aren't typically smart enough to warn you when you inevitably make a mistake and try to save your larger than 256 character string to a varchar(255). If you were to build all of this yourself you would invariably find yourself creating your own types for your ORM and doing a translation from language primitive to database type and back just like I am here. This gets even more complex when an ORM decides to support multiple database engines. Once this becomes more fleshed out you can even have your ORM write the schema query and automatically create your tables from your code.
Here for example I'm gonna go ahead and create a Tag class and then save something.
class Tag extends Model {
public static $tableName = 'tags';
protected $Tag; // this will be a varchar(255) in MySQL, a string in PHP
}
$myTag = new Tag();
$myTag->Tag = 'my tag';
$myTag->save();
With these few simple lines of code we've created a tags table and saved a new Tag "my tag" into our new table. The framework automatically detected the table was missing during the save and created it and then followed through by running the original save. Excellent for bootstrapping new projects or installing software.
Protected? Magic Methods
Traditionally it's common to think that __get and __set are triggered only when a property is undefined. However it is also triggered if you try to access a protected property from outside of the model. When you access a protected attribute from outside of the object it will always trigger __get when retrieving and __set when setting. For this reason I decided to use protected attributes in a Model for mapping.
The way in and out allows us to do some type casting. For example Divergence supports reading a timestamp in Y-m-d H:i:s, unix timestamp, and if it's a string that isn't Y-m-d H:i:s it will try running it through strtotime() before giving up. But that will only ever happen when __set is called thereby starting the chain of events leading to the necessary type casting for that field type. Unfortunately the downside to using a protected in this context is that when you need to access a field inside the object you can't use $this->Tag = 'mytag'; because it won't trigger __set and so what's gonna happen is you will end up messing with the internal data of that field incorrectly. So for the specific context where you're working with the field directly inside of the object itself you should actually use setValue and getValue instead. Frankly you can use __set and __get directly but let's be civilized here. This caveat is why I would like to see the ability for PHP to have __set and __get triggerables configurable to do so on existing object members.
Relationships.
But wait. There's more! Now with the ability to use Attributes for field definitions we can use them for relationship definitions as well.
#[Relation(
type: 'one-one',
class: User::class,
local: 'CreatorID',
foreign: 'ID'
)]
protected $Creator;
#[Relation(
type: 'one-many',
class: PostTags::class,
local: 'ID',
foreign: 'BlogPostID'
)]
protected $Tags;Relationships take Attributes to the next level.
$this->getValue('Tags');This is all you need to pull all the Tags as an array. Most relationship types can be easily expressed in this format.
$Model->Tags // also works but only from "outside"You can run it like this as well from outside of the Model.
PHP in 2023 is blindingly fast.
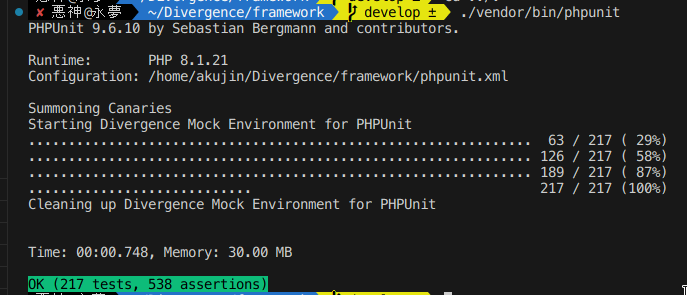
Today the entire suite of tests written for Divergence covering 82% of the code completes in under a second. Some of these tests are generating thumbnails and random byte strings for mock data.
For reference in 2019 the same test suite clocked in at 8.98 seconds for only 196 tests. By the way these are database tests including dropping the database and creating new tables with data from scratch. The data is randomized on every run.
Performance
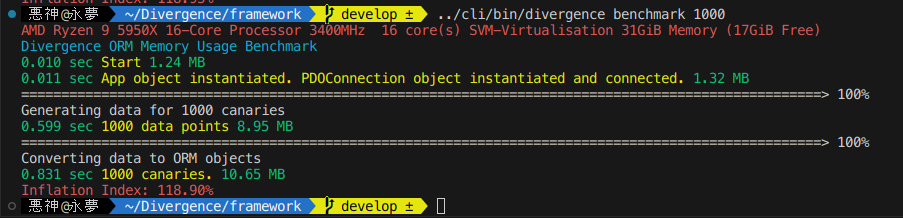
What you are seeing is [time since start] [label] [memory usage] at print time.
The first part where it generates 1000 data points is all using math random functions to generate random data entirely in raw none-framework PHP code. Each Canary has 17 fields meant to simulate every field type available to you in the ORM. Generating all 17 1000 times takes a none trivial amount of time and later when creating objects from this data it must again process 17,000 data points.
Optimizing the memory usage here will be a point of concern for me in future versions of the ORM.
All the work related to what I wrote about in this post is currently powering this blog and is available on Github and Packagist.
Installing XDebug on anything for VSCode in 5 minutes (XDebug 3.x)
This guide is for XDebug 3.x only.
I see a lot of over complicated guides on XDebug so I'll simplify things real quick for everyone.
Visual Studio Code has debugging support out of the box. Click on the Debug icon in the left bar (OS X: ⇧⌘D, Windows / Linux: CTRL+SHIFT+D) then click on the cog icon which should open your launch.json file or create one if none exists.
You must have the PHP XDebug extension installed of course.

Now add this to your launch.json file you have open:
{
"type": "php",
"request": "launch",
"name": "Listen For XDebug",
"port": 9003,
"pathMappings": {
"/var/www/": "${workspaceRoot}"
},
"xdebugSettings": {
"max_children": 256,
"max_data": -1,
"max_depth": 5
},
"ignore": [
"**/vendor/**/*.php"
]
}Make sure you change /var/www/ to where your code is on your local server.
Set this in your php.ini
[xdebug]
xdebug.mode = debug
xdebug.start_with_request = yes
xdebug.idekey = VSCODE
xdebug.client_port = 9003
xdebug.client_host = "127.0.0.1"
xdebug.discover_client_host = 1
xdebug.log="/tmp/xdebug.log"
xdebug.cli_color = 1You might need to do it twice. Once for CLI and once for PHP-FPM!
Typical locations for your php.ini file:
- Linux: /etc/php/{$version}/php.ini
- macOS (Homebrew): /usr/local/etc/php/{$version}/php.ini
Don't forget to restart php-fpm!
Now start the debugger by hitting the green play button.
A few useful life cycle tracking variables every ORM should have
Right now I'm in the unusual position of being responsible for maintaining two different ORMs libraries. Occasionally I want to implement a feature that exists in one of them in the other. One such feature recently came up and I think this is something that all ORMs would benefit from whether or not they are custom written or maintained by the community. In fact after looking into things it looks like some of these already exist in one way or another in some of the most popular ORMs available.
Let's take a look at some of them.
- isNew - False by default. Set to true only when an object that isPhantom is saved
- isUpdated - Set to true when an object that already existed in the data store is saved.
- isPhantom - True if this object was instantiated as a brand new object and isn't yet saved.
- isDirty - False by default. Set to true only when an object has had any field change from it's state when it was instantiated.
Some of these properties might already exist in one form or another in your frameworks. They are simple to implement by simply adding them to the functions in the Model class at different points in the life cycle of the object. Most of them are extremely simple but as you'll see with isDirty consideration might get extremely complex in a hurry.
isNew
The point of isNew is to be able to tell that this object was created during this script execution but was previously saved. Before save it's obvious that an object is new by it's missing primary key. However after saving all evidence of this object being new has been erased. This property lets you know that this object was previously created by you so that if it's part of a large array you can iterate over the items and still know which objects are the "new" ones.
Let's take a look at how this might be useful.
<?php
$cars = Car::GetAll();
$car = new Car();
$car->save();
$cars[] = $car;
foreach($cars as $car) {
if($car->isNew) {
// do something special to the objects we created above even if we saved them since then
}
}
isUpdated
This one is pretty simple. This let's us know something that was already in the data store, has been updated by us since initialization.
isPhantom
Let's us know if we need to Update or Insert this model when saving the object. If Insert this gets set to false right after.
Implementation Details
Let's table isDirty for now and come back to it. For now let's take a look at some code. Here we do a pretty basic boiler plate for the variables we want and how they are manipulated later on.
__construct()
<?php
public function __construct(..., $isDirty = false, $isPhantom = null /* you can
implement these differently but the hydrator needs some way to set these
for an instantiated object */)
{
$this->_isPhantom = false; // this should be set by your model hydrator at time of hydration
$this->_isDirty = $this->_isPhantom || $isDirty;
$this->_isNew = false;
$this->_isUpdated = false;
}save()
public function save() {
if ($this->isDirty) {
// create new or update existing
if ($this->_isPhantom) {
// do insert
$this->_isPhantom = false;
$this->_isNew = true;
} else {
// do update
$this->_isUpdated = true;
}
$this->_isDirty = false; // only if you don't use a function to detect this
}
}So here we can see how it all comes together from initialization to storage. But what about isDirty? What's so complex about it? Well let's take a look.
isDirty
There's multiple ways to implement isDirty and both have positive aspects as well as drawbacks. If your ORM uses direct PHP object properties that map to fields only one is open to you anyway. Let's take a look at what I mean.
If you use an ORM where the fields are not object properties and are in-fact "not real" that means that you can actually implement this as a simple boolean.
For example:
<?php
public function __construct(...) {
$this->_isDirty = false;
}
public function __set($field,$value) {
$this->_isDirty = true;
...
}
public function save() {
...
$this->_isDirty = false;
}The best thing about this method is how light is it on the run time. You simple need one boolean worth of memory space for each object. Unfortunately this method also can't tell when the field was set back to it's original value or if a field was edited but the value remained the same as it was before. So while you may save some memory up front in your run time you might end up wasting a lot more memory resources in your database updating records that have no new data or simply slowing down batch processes sending writes to the database that it will end up wasting time. Furthermore this only works with dynamically allocated "magic" properties.
Your other option is to use a method to test each field for a change and return true or false. Okay but how? By keeping a copy of the "original" field values of course. And this is where this method starts to show it's down sides. You actually end up approximately doubling the amount of memory you need to make this happen. Plus that itself has complexity. For example do you change your original variables after a save? Unfortunately the answer is yes. Simple because you want isDirty to go back to false after running a save. Some things are free though. Any object that is a phantom is dirty by definition.
public function isDirty()
{
if ($this->isPhantom) {
return true;
}
$fields = static::getFields();
foreach ($fields as $field) {
if ($this->isFieldDirty($field)) {
return true;
}
}
return false;
}
public function isFieldDirty($field)
{
if (isset($this->_originalValues[$field])) {
if ($this->_originalValues[$field] !== $this->$field) {
return true;
} else {
return false;
}
}
return false;
}Of course you'll need to set_originalValues in your object during hydration. New objects won't start tracking this until immediately after save. It's worth noting that Laravel's Eloquent implements isDirty in a very similar way.
Closing Thoughts
Most ORMs implement these one way or another out of necessity however it would be nice if ORMS could standardize on these and perhaps start using the same terminology surrounding them. Is dirty is optional for many ORMs when it's beneficial to force a save() even if nothing has been changed simply to updated the modified at timestamp for the record in the data store. Still a well designed ORM should let you do both depending on your needs.
Ignoring SAPI with Symfony VarDumper
<?php
$varCloner = new \Symfony\Component\VarDumper\Cloner\VarCloner();
$cliDumper = new \Symfony\Component\VarDumper\Dumper\CliDumper();
echo $cliDumper->dump($varCloner->cloneVar($query), true);
Quick way to output full text instead of HTML when SAPI is not CLI
The case for system wide dependency injection in PHP
So first let me clarify what I mean when I say "system wide dependency injection".
The typical PHP Composer project offers "project-wide" dependency injection. The autoloader is made for your project and you simply require that one file. However, with other languages it's typical for dependencies to be in a shared folder for the entire system.
In composer we could use a "global" directory in global mode as well like this.

The problem is it's only global "for you". So if you decided to run composer global for another user all the packages you have installed would be different. So it's not global. Not even system-wide really since the home directory might not allow read from other users.
So neither of these modes in composer are really system wide.
In other languages system wide dependencies are stored like so.
For example here's Python.

Perl too.

And Ruby.

Okay so what about PHP?
To fill this hole some Linux developers who choose to include PHP code directly in the system have started to build packages for their distro's package managers.

Here we have the install script for symfony-console in portage. You can see the files are actually stored in /usr/share/php. Unfortunately these files don't have automatically generated autoloaders by composer making integrations very messy.

Portage users aren't the only ones.

Clearly some users choose to install PHP code for use system wide.
/usr/share/ or /usr/lib
Let's check the Linux Foundation's documentation on the topic.


Even though PHP code isn't architecture dependent, in my opinion, it's more of a library for programming so to that end I think it makes more sense to use /usr/lib or in my case /usr/lib64 just like other scripting languages. It would also avoid the messy businesses of integrating with none composer package managers.
I decided to go ahead and experiment with this idea.
I forked composer and made a composer system command. Just like composer global sets the folder to ~/.config/composer/, with the system command it instead sets the folder to /usr/lib64/php or /usr/lib/php if they exist in that order. You must create /usr/lib{64}/php yourself.
The fork of composer is available here: https://github.com/hparadiz/composer
I then loaded in some really awesome PHP libraries.

With this newfound power to no longer have to bundle libs with my scripts I made a database backup utility for this blog in 50 lines of code with SSH tunneling that drops sql.gz to my local home folder.
Feel free to fork it and make your own.

I had the script output to a Dropbox folder since I have it running already. Which is awesome since that's three locations and one of them is managed for me. I'll be hacking at this some more but for now I like this starting place.
I like that this script is fully portable and editable wherever it is. If I compile it to a phar it would be difficult to make changes or loop it for multiple databases without setting up an entire build configuration despite that logic being relatively simple even for a novice.
For me, at least, the reasons to allow composer to manage dependencies at a system wide level instead of having other package managers do it is self evident.
Installing XDebug on anything for VSCode in 5 minutes (XDebug 2.x)
Update 2/25/2021: This guide is for XDebug 2.x only.
I see a lot of over complicated guides on XDebug so I'll simplify things real quick for everyone.
Visual Studio Code has debugging support out of the box. Click on the Debug icon in the left bar (OS X: ⇧⌘D, Windows / Linux: CTRL+SHIFT+D) then click on the cog icon which should open your launch.json file or create one if none exists.
You must have the PHP XDebug extension installed of course.
Now add this to your launch.json file you have open:
{
"type": "php",
"request": "launch",
"name": "Listen For XDebug",
"port": 9000,
"pathMappings": {
"/var/www/": "${workspaceRoot}"
},
"xdebugSettings": {
"max_children": 256,
"max_data": -1,
"max_depth": 5
},
"ignore": [
"**/vendor/**/*.php"
]
}Make sure you change /var/www/ to where your code is on your local server.
Set this in your php.ini
[xdebug]
xdebug.remote_enable = 1
xdebug.remote_autostart = 1
xdebug.profiler_enable_trigger = 1You might need to do it twice. Once for CLI and once for PHP-FPM!
Typical locations for your php.ini file:
- Linux: /etc/php/{$version}/php.ini
- macOS (Homebrew): /usr/local/etc/php/{$version}/php.ini
Don't forget to restart php-fpm!
Now start the debugger by hitting the green play button.
How I gamified unit testing my PHP framework and went from 0% unit test coverage to 93% in 30 days
In 2018 I was taking a break from work. I wanted to upgrade my skills while looking for new opportunities. My previous job was working in a NodeJS environment which I certainly enjoy in many ways but PHP is actually my favorite language to work with so I wanted to challenge myself to learn something new.
I had two goals really. The first was to learn. I wanted to see what continuous integration was actually all about. The second was to prove the rock solid design of the ORM library I've been using for the past five years. It was passed around by a few local developers I knew but using it in production on new projects became an increasingly hard battle as most people wanted to use other ORMs that were more popular. It felt like without unit tests and a code coverage badge and a page on packagist I had no legitimacy. With that in mind I got to work.
With this post I hope to write down what I learned in a clear, concise, and easy to understand way for moderately experienced PHP developers and for myself.
Code Coverage
Code coverage is a line by line yes/no report from PHPUnit that simply says if that line has been tested or if it has not. You can get a code coverage report on your own computer just by running PHPUnit with XDebug enabled. Just add the command line switch --coverage-clover clover.xml when you run PHPUnit.

Here you can see I'm telling phpunit where to put the code coverage report. You will need Xdebug as well for the feature to be available. A clover.xml file by itself though is just raw data and without a proper interface to view it you won't really be able to make much use of it.
View the Code Coverage Report
One website which provides this is Codecov.io
They give you a simple to use bash install script.
You can run it right now with the report you already generated right in the terminal.

You should probably sign up at this point and claim your free private repository. If your project is open-source you can have as many as you want!
Once signed up you will find the token in the repository settings. They give you a few ways to specify the token there.

Now you can run the report uploader script from above again.

Now that it uploaded you can take a look at the report.

As you can see my initial commit had terrible code coverage. The code was still not even organized as per PSR-4 and PHP League standards but at least I had base line and there's no where to go but up.
The PHP League
The PHP League of Extraordinary Packages make a slew of excellent packages but they also provide a skeleton template available in this Git repository that documents the proper modern way of organizing a PHP project. It was invaluable to me as a reference.
It shows you how to configure badges, continuous integration, organize your source code, and lots of other best practices.
Continuous Integration
Now that we know the code coverage report works we can setup continuous integration. I'd recommend TravisCI but if you have Bitbucket premium it comes with 500 free minutes of their continuous integration solution called Pipelines. Pipelines and TravisCI are basically just plugins for Github or Bitbucket or any other host of your Git repository. They get event hooks when your code gets pushed to your Git host and then they run a bash script in a container with your code. You can then run tests, do builds, and setup other automated solutions for your source code. But how you ask? Well there's a YAML file you have to create. In this example I will show my Travis file. The source is available here.
language: php
php:
- '7.1'
- '7.2'
addons:
apt:
sources:
- mysql-5.7-trusty
packages:
- mysql-server
- mysql-client
before_install:
#- sudo mysql -e "use mysql; update user set authentication_string=PASSWORD('divergence_tests') where User='root'; update user set plugin='mysql_native_password';FLUSH PRIVILEGES;"
#- sudo mysql_upgrade
#- sudo service mysql restart
- mysql -e 'CREATE DATABASE IF NOT EXISTS test;'
install:
# Install composer packages
- travis_retry composer update --no-interaction --no-suggest
- travis_retry composer install --no-interaction --no-suggest
# Install coveralls.phar
- wget -c -nc --retry-connrefused --tries=0 https://github.com/php-coveralls/php-coveralls/releases/download/v2.0.0/php-coveralls.phar -O coveralls.phar
- chmod +x coveralls.phar
- php coveralls.phar --version
before_script:
- mkdir -p build/logs
- ls -al
script:
- ./vendor/bin/phpunit --coverage-clover build/logs/clover.xml
after_success:
# Submit coverage report to Coveralls servers, see .coveralls.yml
- travis_retry php coveralls.phar -v
# Submit coverage report to codecov.io
- bash <(curl -s https://codecov.io/bash)
# Tell Travis CI to monitor only 'master' branch
branches:
only: master
# Specify where the cache is so you can delete it via the travis-ci web interface
cache:
directories:
- vendor
- $HOME/.cache/composerThis file basically tells Travis what to do.
- Which versions of PHP to test with.
- Which branches of the git repo to run against.
- Sets up the localhost MySQL environment for our PHPUnit tests in the container.
- Runs composer dependency installer
- Runs PHPUnit
- Uploads the code coverage report.
The best part? You get an email at the end with what got fixed or any new problems. TravisCI also runs a rudimentary static analyzer on your code bringing up problems with the source as well as your PHPDoc notation which adds even more added value to having your unit tests run automatically every time you update a given branch.
In Github you even get this view available to you all in one place.

The Road to 90%
Initially you come to the realization that your ability to increase the score through your simple and basic helper classes lets you score a few easy wins early on. Ripping out old, unused, verbose, and unclean code also lowers your total code count thereby increasing your overall coverage score. Sometimes you actually have to edit your code to make it easier to test. Standalone global code in PHP files becomes even more onerous as testing that code becomes next to impossible. Let's take a look at a few examples.
Editing your code to make it easier to test.
Here I need to fake the stream php://input which is what we parse for raw JSON data sent via POST. Doable but only by creating your own fake stream and at a different address.

But it's okay because it enabled this simple test. Which increased the coverage of that one file by 13.33%. By the way virtual streams are pretty awesome. Check out the test below.
/**
* @covers Divergence\Helpers\JSON::getRequestData
*/
public function testGetRequestData()
{
$json = '{"array":[1,2,3],"boolean":true,"null":null,"number":123,"object":{"a":"b","c":"d","e":"f"},"string":"Hello World"}';
vfsStream::setup('input', null, ['data' => $json]);
JSON::$inputStream = 'vfs://input/data';
$x = json_decode($json,true);
$A = JSON::getRequestData();
$B = JSON::getRequestData('object');
$this->assertEquals($A, $x);
$this->assertEquals($B, $x['object']);
}Ripping Out Old Code
Here I found a function that was previously used to manually prettify JSON used way back when PHP didn't have this functionality built in. Sometimes it's sad to delete old code. Especially when it's will written, clean, and easy to understand. But sometimes it's just time to let it go and let someone else worry about it.

Lets just say I cut a lot of random old code. This obviously had a great impact on the readability and cleanliness of the code going forward.
What I did for Database Unit Testing
Eventually I ran out of low hanging fruit testing things that had nothing to do with the database and then... it was time for the database. A number of issues came up.
- A test database would need to be created on my laptop that mirrors the TravisCI config to avoid having to write extra logic. I added a new 'testing' default config to the default database config that comes with the framework.
- I needed to add some bash terminal commands to the TravisCI file above to make it reset the database every time.
- I need a way to run some code the unit tests need to run before all the unit tests would begin to setup a bunch of fake data.
To solve this I created a class which implements PHPUnit's PHPUnit_TestListener interface. I previously wrote a post on doing this in detail.



So here we initialize our mock application and set the database connection to use the tests-mysql config.
App::setUp is actually where the mock data is created.
Fake it till you make test it
To make this database testing thing actually work I actually made a fake site that would live in the PHPUnit environment. I gave it a separate namespace in the tests namespace.

The App class from earlier? You can view it here.

As I wrote more unit tests I added more and more Tag creation stuff to this function. As I created more and more mock data attacking the more and more complex situations in my tests became easier and easier.
Lowering Code Complexity
As you get further and further into testing your code you will come to some code which has lots of complex conditional statements with multiple conditions which might potentially have any n-number of possible combinations. By breaking out your code into ever smaller and smaller methods it is possible to make every method have a very low number of combinations hopefully in the single digits.
For example the increased conditional complexity of the code below make it difficult to get tests which achieve 100% unit test coverage because you need to provide every possible permutation of conditionals and if there are more obviously there could be more conditions.

I changed the above to be a switch($options['type']) instead and broke out each type into it's own function. The new functions become much easier to test with fewer conditional permutations to keep track of.


Writing tests for these much simpler functions becomes almost trivial and the code looks much cleaner too.
Implementing a Test Listener in PHPUnit 7
I've recently been setting up PHPUnit for my PHP Framework Divergence and one change from PHPUnit 7 from the previous versions is that the TestListener no longer extends PHPUnit\Framework\BaseTestListener class (which has been removed entirely). Instead you can use the interface PHPUnit\Framework\TestListener.
Make sure you register the listener in your phpunit.xml file.
<listeners>
<listener class="Divergence\Tests\TestListener" file="./tests/Divergence/TestListener.php"></listener>
</listeners>Here's a simple example.
<?php
namespace Divergence\Tests;
use PHPUnit\Framework\TestCase;
use PHPUnit\Framework\TestListener as PHPUnit_TestListener;
use PHPUnit\Framework\Test;
use PHPUnit\Framework\TestSuite;
class TestListener implements PHPUnit_TestListener
{
public function __construct() {} // does nothing but throws an error if not here
public function addError(Test $test, \Throwable $e, float $time): void
{
//printf("Error while running test '%s'.\n", $test->getName());
}
public function addWarning(Test $test, \PHPUnit\Framework\Warning $e, float $time): void
{
//printf("Warning while running test '%s'.\n", $test->getName());
}
public function addFailure(Test $test, \PHPUnit\Framework\AssertionFailedError $e, float $time): void
{
//printf("Test '%s' failed.\n", $test->getName());
}
public function addIncompleteTest(Test $test, \Throwable $e, float $time): void
{
//printf("Test '%s' is incomplete.\n", $test->getName());
}
public function addRiskyTest(Test $test, \Throwable $e, float $time): void
{
//printf("Test '%s' is deemed risky.\n", $test->getName());
}
public function addSkippedTest(Test $test, \Throwable $e, float $time): void
{
//printf("Test '%s' has been skipped.\n", $test->getName());
}
public function startTest(Test $test): void
{
//printf("Test '%s' started.\n", $test->getName());
}
public function endTest(Test $test, float $time): void
{
//printf("Test '%s' ended.\n", $test->getName());
}
public function startTestSuite(TestSuite $suite): void
{
if($suite->getName() == 'all') {
printf("TestSuite '%s' started.\n", $suite->getName());
}
}
public function endTestSuite(TestSuite $suite): void
{
if($suite->getName() == 'all') {
printf("TestSuite '%s' ended.\n", $suite->getName());
}
}
}