From the Terminal
I "Rewrote" My ORM Again with AI. And Ended Up Benchmarking Every PHP ORM in the Process.
You may or may not have read my other blog posts about how
How I gamified unit testing my PHP framework and went from 0% unit test coverage to 93% in 30 days
(7 years ago!) or about how
PHP attributes are so awesome I just had to add attribute based field mapping to my ORM
I've been writing ORMs by hand for 20+ years. This isn't even the only one I've worked on. So with ML I've been able to basically get to where I want to be. If you prefer blog posts written by humans I can attest that nothing in this post is written by AI.
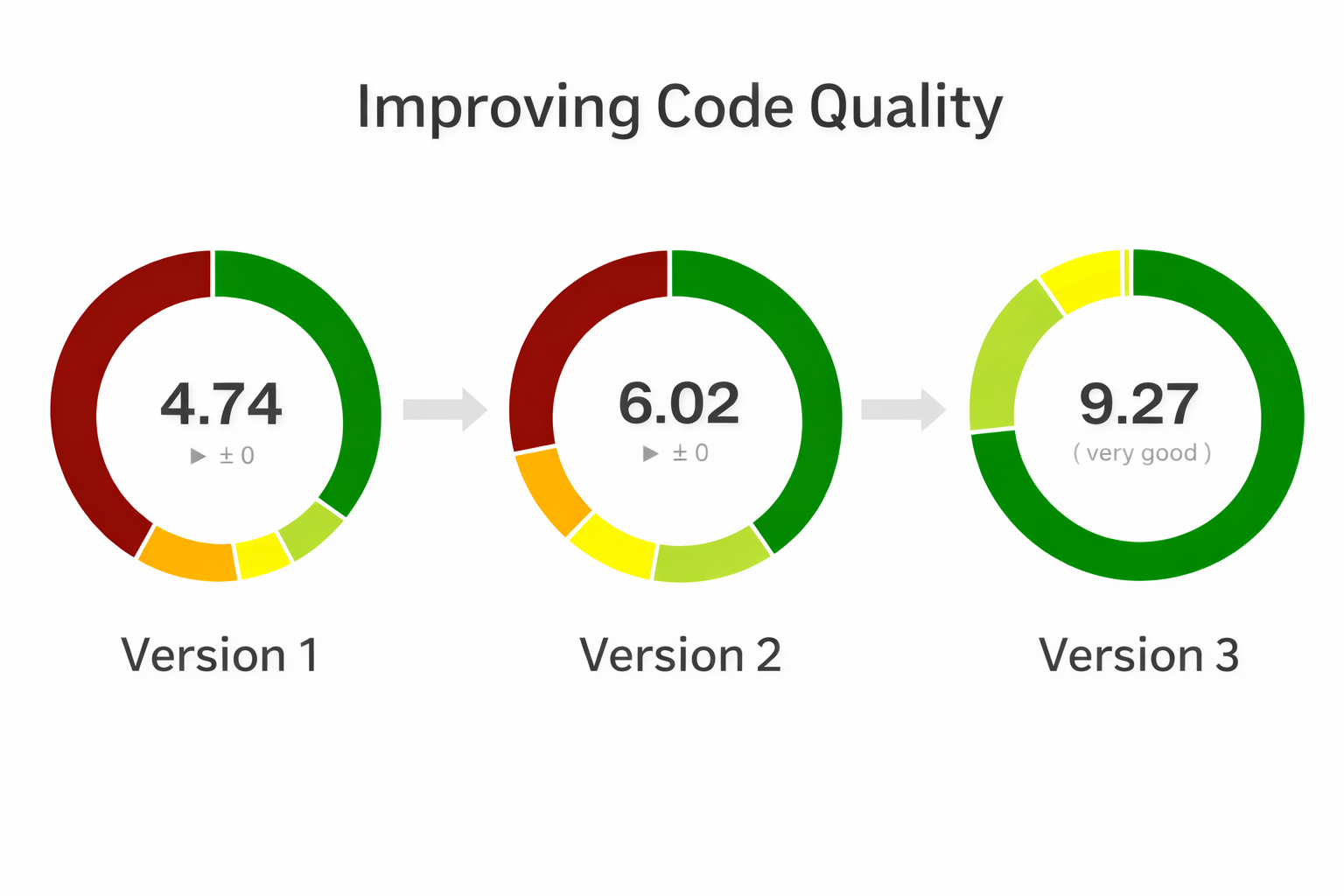
Prior to version three I had already been wanting to improve code quality and was already going in that direction.
In version three I was able to find ways to improve code quality substantially but it all built on top of the work I had done by hand moving from Version 1 to 2.
Version 1 of Divergence was mostly dominated by a large ActiveRecord monolith class paired with a MySQL class. Together they were able to stand up an impressive PHP 5.x era ActiveRecord ORM with a good track record that stood up well through PHP 7.4. PHP 8 however introduced attributes and there is where I started to think critically about Code Complexity and way of breaking up the code into smaller chunks more critically.
Code Complexity? What are you talking about?
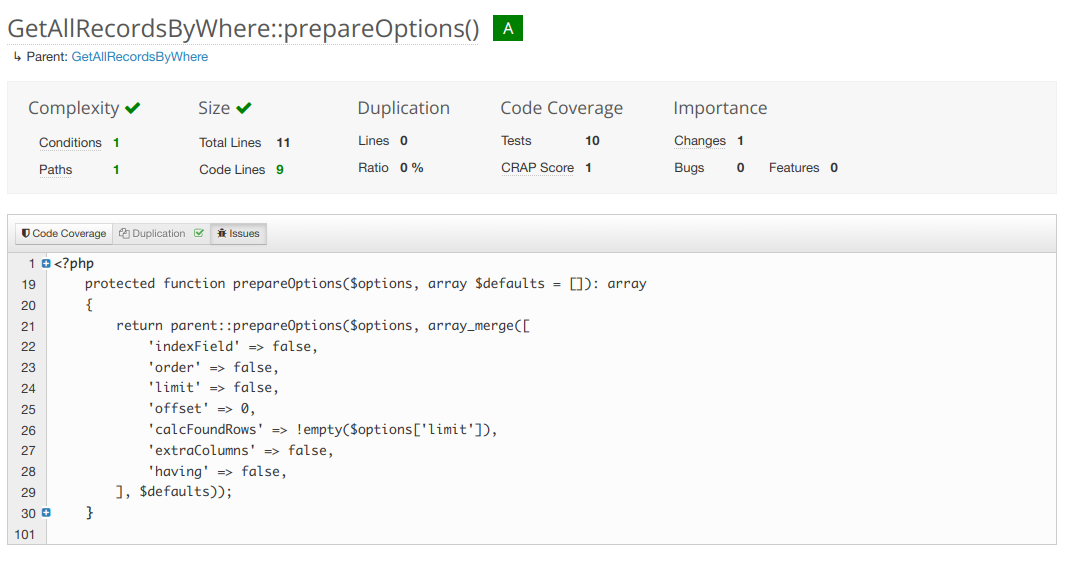
Code complexity is a measure of how many pathways your code can take. The fewer, the simpler, the easier it is to write a unit test that covers 100% of the things your function can do.
Above is a fairly simple and not very complex function.
On the other side of the fence we've got the most complex function in the framework at the moment which is my next target for refactoring.
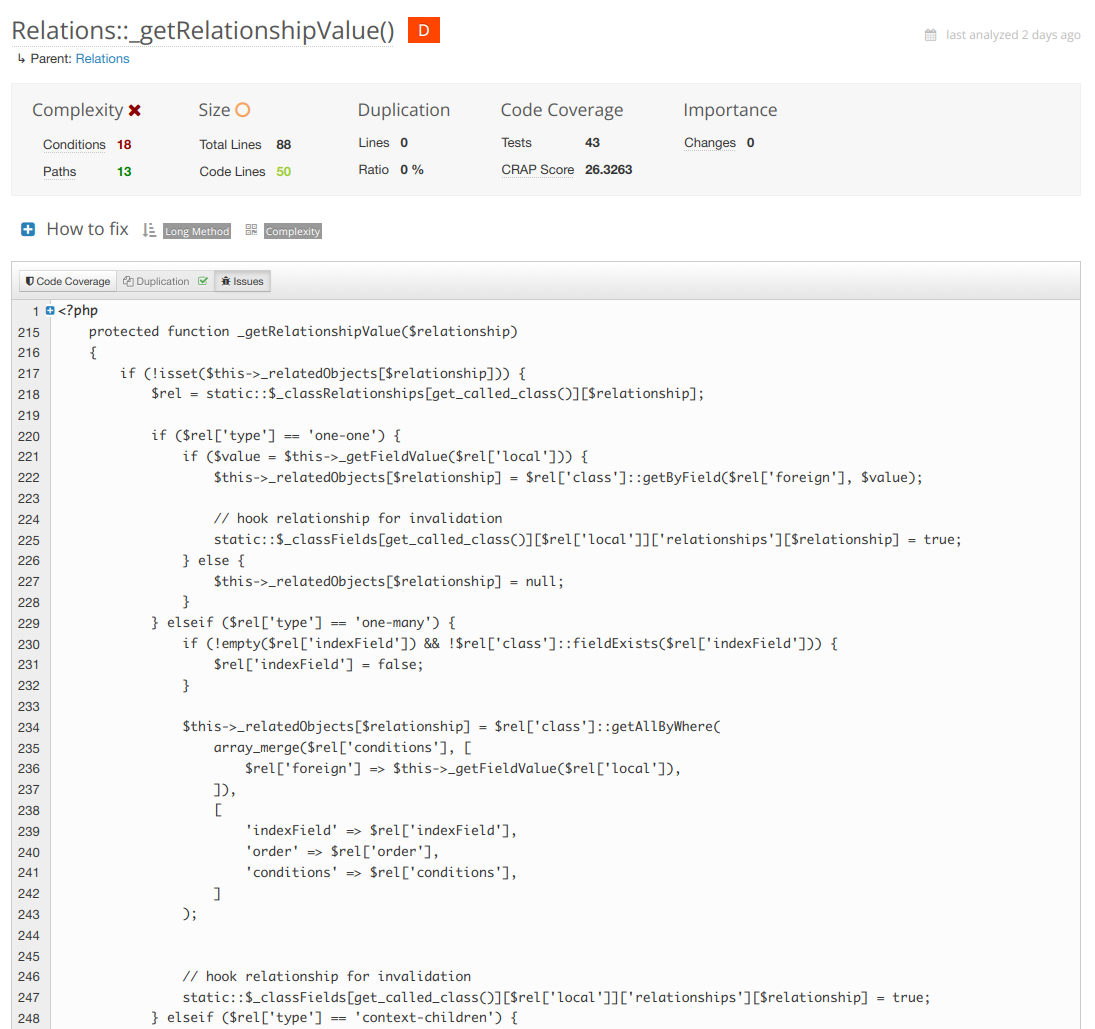
In this case the refactor is obvious. Break up each of the relationship types into smaller method calls inside the same class. Each one responsible for only it's own thing. Complexity drops. Your tests become far simpler and targeted.
Above is the worst class now... in version three. But back in version one the code was in a way worse shape with complexity.
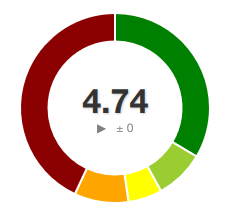
Version 1 of Divergence - Large Monolith Classes
In 1.0 ActiveRecord was handling almost everything including mapping type values to MySQL type values so in 1.1 I introduced the "FieldSetMapper" abstraction. which allows a model to set it's own Field Mapper if necessary. This lowered ActiveRecord's complexity in a great direction but it was still responsible for instantiating and hydrating new objects, getters for objects, as well as the life cycle of the object. So pretty much still a monolith.
The next thing to refactor was how queries were being written. Which frankly in ActiveRecord and VersionedRecord there where only a handful of spots where a SELECT, UPDATE, INSERT, or DELETE was being generated so it was an obvious spot to start doing query writing through a class. I implemented __toString() here so all the existing string handling just keeps doing what it was doing. Tests passed no problem. At this point the ground work was laid for being able to implement other storage engines besides MySQL for the first time. This is also where I started to think of "Getters" as separate from the ActiveRecord class.
In CS-coder speak a Getter is essentially a factory. A place where we grab data out of the storage engine like MySQL and then shove that data into PHP objects. Getters have two parts. A query part and a hydration part. Getters are broken up into two types. Multiple records and single records. So here they are. Some of them like getByWhere have a direct all version getByAllWhere. The only difference is getting one of itself to multiple of itself.
| Single | Multiple |
|---|---|
getByID |
|
getByHandle |
|
getByContextObject |
getAllByContextObject |
getByContext |
getAllByContext |
getByField |
getAllByField |
getByWhere |
getAllByWhere |
getByQuery |
getAllByQuery |
getRecordByField |
|
getRecordByWhere |
getAllRecordsByWhere |
getAllByClass |
|
getAll |
|
getAllRecords |
Okay so why? Why do that?
A lot of ORMs just do this. A factory class has the getters and spits out Employee objects. Simple. Well in the best case. Something like this.
<?php
$employees = new EntityManager('Employee')->all();In Divergence I do this:
<?php
$employees = Employee::getAll();This has not changed since Version 1 either. From the predecessor of this framework Emergence to now this code is still valid. I'm not gonna say my changes haven't broken user space but they certainly did so in ways that are easy to port. When you have these getters registered as static methods under your class you get a global access to these models from anywhere in your code. They become singleton globals we can use anywhere.
In version 2 of Divergence I started to abstract them out by making them a trait you could attach to your Models. The default Class "Model" would automatically assign them so the global method calls persisted through the refactor and again no tests were harmed. Yet now they were not in ActiveRecord and made the code far less complex.
It became immediately apparent that every single function in the table above was either using instantiateRecord or instantiateRecords. After running the query the return data had to be converted to PHP objects and that's where it happened. So along with the above methods I was able to also move hydration into the Getters trait and a few other helper methods. They technically still accessed field and relationship mappers in the ActiveRecord class but hydration was still something we could move out of ActiveRecord as long as the mapping field mapping was calculated once. This is around the time when I wrote my blog post about attribute field maps in PHP 8.
At the same time I also converted my controllers to use PSR7 and PSR15 handlers and emitters. The "old school" way is to just echo, print, and run header() whenever you please in your controller. The new way is to generate an HTTP controller object, set everything, and then pass it to an "Emitter" that does the printing and http handling. To be honest that deserves it's own blog post but suffice to say it lowered complexity further. At the same time I added Media handling classes that needed heavy refactoring. But at least for the moment I was able to take the wins and get the score from a 4.7 to a 6 with these changes. Still to hit the 9 I was looking for it would take some heavy thinking on how to tackle the next iteration. And all this was BEFORE a single AI algorithm had been used.
So in version 2 I identified these goals for version 3.
- I want to support SQLite and PostgreSQL
- To do so the Connection must be aware of it's engine and be tied to a given Model's instantiation and Hydration and the Query Writer needs to know about the Connection's Storage Engine in order to write proper syntax.
- By providing a Factory class we can keep that state with the instantiation and hydration cleanly.
- Factory classes also make it easier to test things in isolation.
- Using __call we can create different types of methods that used to live in ActiveRecord that are converted to their own classes.
- Getters that used to exist in ActiveRecord can still run statically if they are registered with the Model using __call.
- What's left after removing these things from ActiveRecord is events and those can then cleanly be moved into their own classes as well.
All this abstraction sounds like a lot but we went from ActiveRecord doing manual INSERT and UPDATE query writing hardcoded MySQL syntax. Instead now when we cast from SQL to PHP and back and the system is neatly organized and any overrides can happen in the most appropriate place. Super simple to test. The query writers for each storage engine work against whatever the active connection is and only have overrides when necessary.
Should Models Even Have Getters and Setters to Get Records Of Themselves From the Storage Engine?
PHP is inherently procedural and owing to it's roots. Because it's procedural things are happening one at a time from beginning to end. When scaling you might have a read replica of the database that is used as a backup. In that case you might even run something like setConnection(). When your secondary connection is the same storage engine things are easy but what if it's a totally different type of SQL? That's basically why it's better to have a Factory or "Entity Manager". You might want to create two for the same Model for two different connections or more than that even. But...... 99% of projects won't ever need it. So I want to serve both schools of thought. And that is why in version 3 of Divergence I decided to introduce a Factory class for the first time. Now all the connection handling, storage engine SQL translation, mapping, and object hydration doesn't have to live in ActiveRecord. The thing is you can still use __call to build "fake" methods so I did just that for the Getters that used to live in ActiveRecord. So you can still use them and it will make you the Factory in the background but if you really need the abstraction you can also make the factories and manage them manually.

New Hydration Method
In version three besides the difference in where this stuff is happening I also abstracted out the way that objects are instantiated.
In Divergence 1 and 2 we did the classic late static binding.
Anyway here's version 3 of Divergence.
It's running this site too.
Here are my benchmarks right now
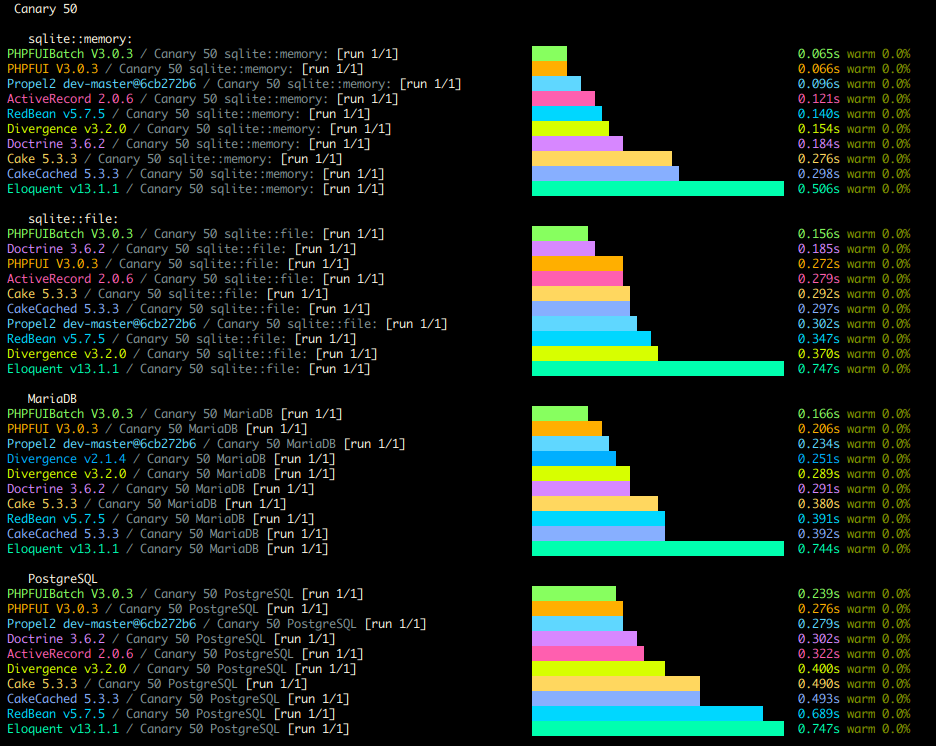
In the process of doing all this I really wanted a good profiler and test case so I ended up building a new PHP Benchmarking Suite which I call "The PHP Bench". The screenshot above is the results command doing it's thing on the CLI. But then I made a website for it where results can be viewed online.

I'm particularly proud of the architecture of this benchmark. I hand designed the Models to simulate several types of data. Canary in particular handles every type of field my framework supports. But then I also have fixed ints, variable strings, and fixed strings, among other benchmarks you can run. Every type shows a clear and distinct performance profile among the various frameworks.
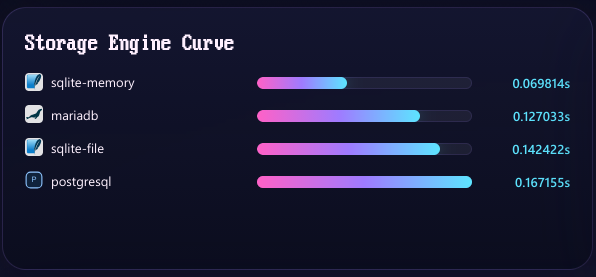
Each framework gets their own composer.json and isolated vendor path that only gets required for their individual test so none of the frameworks can really interact with each other or cause conflicts. The findings were completely unexpected to me but I'm proud to say my self made ORM is among the world's best.
Now that I have a profiler and benchmark I can use my next step is to scaffold some first to save() and some first to query profilers against some of these and see if I can shave another 0.02-0.05 ms per operation. I never really thought I'd get to hit this milestone so soon. So that's nice.
I honestly feel like a dog that finally caught the truck. Now what.

Haha just kidding. There's so much I can do with this now! With agents I can just throw the docs at it. I even got a minimal context size one written up for MVPs. I've already got this blog working of course but what's next? You can't see it but I already got my admin page slightly tricked out.
I didn't even use react. I told it to use classic jquery ajax on top of vanilla javascript so it's dead simple.
So what else is there to do? I've been wanting to tackle some federated things and see how far I can get. In particular I think it would be fun to turn this blog into a federated node and implement the ActivityPub protocol.